神经网络求解PDE入门
1 引言
本文探讨了应用深度学习方法求解偏微分方程的三种代表性方法:
- Deep Ritz Method (Ritz):基于变分原理,将求解PDE问题转化为一个能量泛函的最小化问题。
- Physics-Informed Neural Networks (PINN):通过在损失函数中加入PDE残差项和边界条件项,将物理规律编码到神经网络中。
- Transferable Neural Networks (TransNet):利用迁移学习的思想,首先预训练一个通用模型,然后针对特定问题进行微调,以提高求解效率和精度。
为深入理解这些方法的特性,本文设计了一系列实验,主要围绕一维和二维的泊松方程(Poisson’s Equation)展开。
2 问题描述
本次实验求解的方程是泊松方程,其一般形式为:




并带有狄利克雷边界条件:


对于一维 Poisson 方程 Equation 1,设置精确解


对于二维 Poisson 方程,设置精确解


3 实验
3.1 实验一:一维泊松方程四种组合对比
本实验采用两种不同的网络结构(DeepRitzNet, PINNNet)和两种不同的损失函数构建方式(Ritz变分法, PINN最小二乘法)进行组合对比。
3.1.1 网络结构
DeepRitzNetDeepRitzNet 和 PINNNetPINNNet 均采用基于残差连接的神经网络结构,以确保公平比较。
- 结构: 6层网络,每层包含64个神经元。
- 激活函数:
tanhtanh函数。 - 输入: 空间坐标

 。
。 - 输出: 对应坐标点上的解的近似值

 。
。 残差连接:
DeepRitzNetDeepRitzNet: 每2层添加一个跳跃连接
 ,共3个残差块。
,共3个残差块。PINNNetPINNNet: 每1层添加一个跳跃连接,共6个残差块。
- 嵌入矩阵: 使用

 矩阵将输入维度映射到隐藏层宽度,便于残差连接。
矩阵将输入维度映射到隐藏层宽度,便于残差连接。
3.1.2 算法构造
3.1.2.1 边界条件处理
本实验采用了一个巧妙的技巧来自动满足齐次Dirichlet边界条件 
 。
。
定义包络函数:


对于一维情况:
 ;对于二维情况:
;对于二维情况:
 。
。
网络的最终输出定义为:


其中 
 是神经网络的原始输出。由于在边界
是神经网络的原始输出。由于在边界 
 上至少有一个坐标为0或1,因此
上至少有一个坐标为0或1,因此 
 ,从而自动满足边界条件
,从而自动满足边界条件 
 。
。
这种方法的优点是:
- 硬约束:边界条件被严格满足,而非通过惩罚项软约束。
- 简化训练:无需在损失函数中添加边界惩罚项。
- 提高精度:避免了边界条件近似带来的误差。
3.1.2.2 Ritz 变分法
该方法旨在最小化与PDE对应的能量泛函。对于泊松方程,其能量泛函为:


由于边界条件已通过包络函数自动满足,损失函数仅需对能量泛函进行数值积分:


其中,
 是网络输出对输入的梯度,可以通过自动微分轻松获得。
是网络输出对输入的梯度,可以通过自动微分轻松获得。
3.1.2.3 PINN 最小二乘法
该方法直接将PDE的残差作为损失函数。由于边界条件已自动满足,损失函数仅包含内部点的PDE残差:


其中,
 是网络输出对输入的二阶导数(拉普拉斯算子),同样可以通过自动微分计算。
是网络输出对输入的二阶导数(拉普拉斯算子),同样可以通过自动微分计算。
3.1.3 实验设置
| 参数 | 说明 |
|---|---|
| 问题域 |   |
| 优化器 | Adam 优化器,学习率为 1e-31e-3,  |
| 学习率调度 | StepLR,每1000步衰减为原来的95% |
| 训练轮数 | 5000 epochs |
| 内部点 | 在域   内均匀随机采样 512 个点 内均匀随机采样 512 个点 |
| 边界条件 | 通过包络函数 自动满足,无需采样边界点 |
| 随机种子 | 每个组合使用不同的种子(43-46)以确保公平比较 |
3.1.4 实验结果与分析
采用相同的网络结构与两种损失函数进行组合,得到四种实验配置。结果汇总如下:
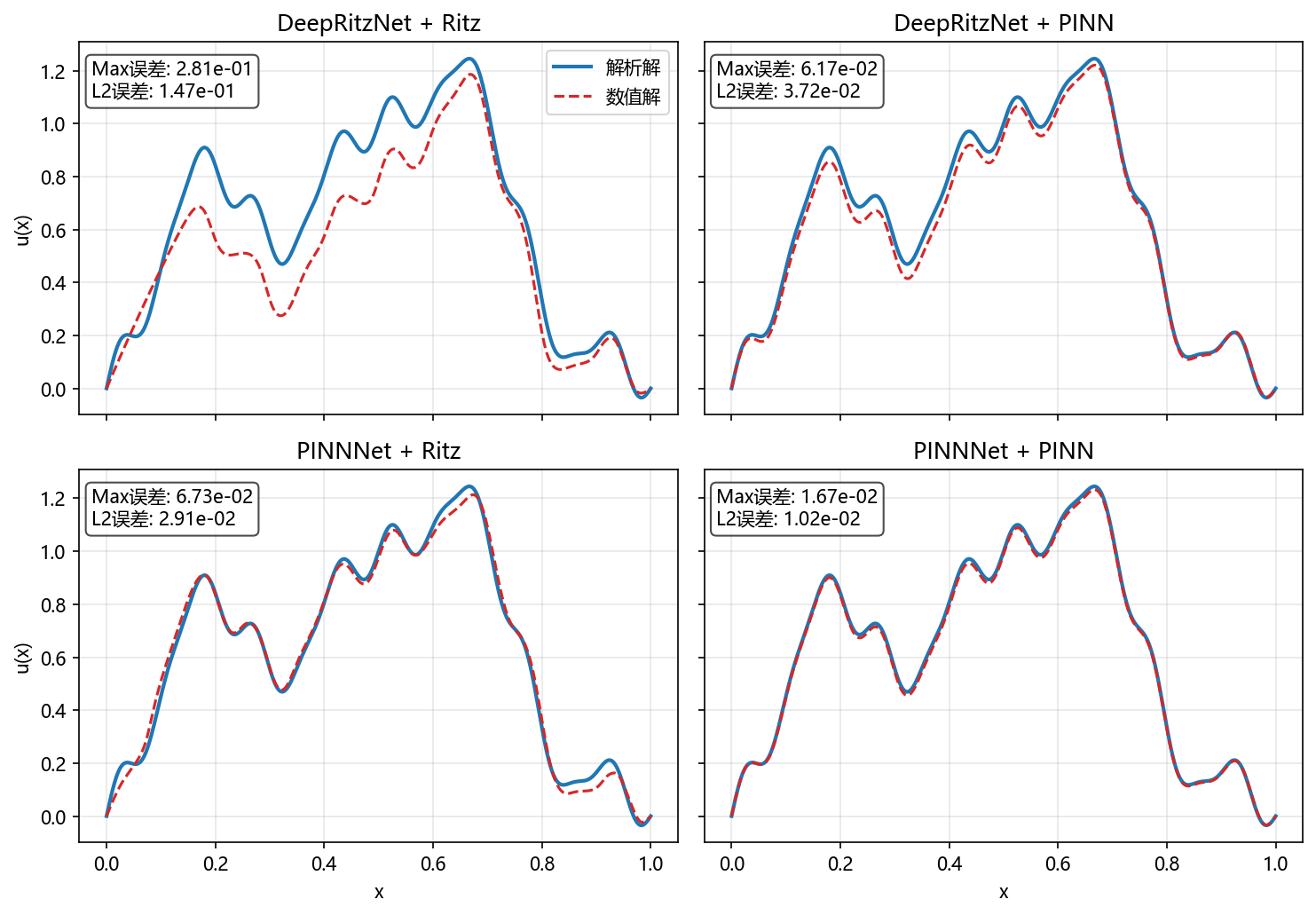
| 模型 | 求解方法 (损失函数) | Max误差 | L2误差 | 时间(s) |
|---|---|---|---|---|
| DeepRitzNet | Ritz | 2.81e-01 | 1.47e-01 | 50.08 |
| DeepRitzNet | PINN | 6.17e-02 | 3.72e-02 | 75.06 |
| PINNNet | Ritz | 6.73e-02 | 2.91e-02 | 47.58 |
| PINNNet | PINN | 1.67e-02 | 1.02e-02 | 76.15 |
精度对比:
- PINN损失函数表现更优: 无论是用
DeepRitzNetDeepRitzNet还是PINNNetPINNNet,采用PINN的最小二乘损失函数得到的精度都显著高于采用Ritz的变分损失函数。PINNNetPINNNet+PINNPINN组合取得了最佳的精度(Max误差1.67e-02, L2误差1.02e-02)。 - Ritz方法的不稳定性:
DeepRitzNetDeepRitzNet+RitzRitz的组合表现最差,误差比其他组合高出一个数量级。这可能与Ritz方法对网络结构、采样点分布或超参数更敏感有关。变分法的优化目标(能量泛函)与解的误差(如L2范数)并非直接等价,可能导致优化过程不那么直接。
- PINN损失函数表现更优: 无论是用
时间对比:
- PINN方法耗时更长: 采用PINN损失函数的训练时间(约75秒)明显长于采用Ritz损失函数(约50秒)。这是因为PINN需要计算二阶导数(拉普拉斯算子),而Ritz方法只需要计算一阶导数(梯度)。在自动微分中,计算高阶导数通常需要更多的计算资源和时间。
对于这个一维泊松问题,PINN方法以更长的训练时间为代价,换取了更高的求解精度和稳定性。PINNNetPINNNet + PINNPINN 是最优组合。
3.2 实验二:二维泊松方程 TransNet 评估
对于二维问题,本实验采用 TransNet 方法进行求解。TransNet(Transferable Neural Networks)是一种基于可迁移神经特征空间的PDE求解方法,其核心思想是将神经网络参数重参数化,使得隐藏层参数具有良好的迁移性,从而可以在不同的PDE问题之间共享。
3.2.1 网络结构
TransNet 采用单隐层神经网络结构,但通过特殊的参数化方式实现了强大的表达能力:
- 输入维度: 2(空间坐标

 )
) - 隐藏层神经元数: 500个
- 激活函数:
tanhtanh函数 - 输出维度: 1(解的近似值

 )
)
参数重参数化:传统神经网络的隐藏层表示为 
 ,TransNet 将其重参数化为:
,TransNet 将其重参数化为:


其中:

 是单位向量(
是单位向量(
 ),表示分割超平面的法向量
),表示分割超平面的法向量
 是标量,表示超平面到原点的距离
是标量,表示超平面到原点的距离
 是形状参数,控制激活函数的陡峭程度
是形状参数,控制激活函数的陡峭程度
参数采样策略:
- 方向 :从标准高斯分布

 采样后归一化
采样后归一化 - 截距 :从均匀分布

 采样(本实验中 radius = 1.5)
采样(本实验中 radius = 1.5) - 形状参数 :通过高斯随机场(GRF)辅助函数离线搜索最优值
3.2.2 算法构造
TransNet 的求解过程分为两个阶段:
3.2.2.1 阶段一:特征空间构建
神经元生成:根据上述采样策略生成500个神经元的参数

 。
。形状参数优化:使用高斯随机场(GRF)作为辅助函数,通过网格搜索找到最优的
值。具体步骤:- 在单位球内均匀采样测试点
- 生成多个GRF函数作为目标函数
- 对每个候选 值,使用最小二乘法拟合GRF
- 选择平均拟合误差最小的 值
本实验中,搜索范围为

 ,网格大小为50,使用50个GRF函数,每个GRF使用1024个随机傅里叶特征(RFF),相关长度为2。
,网格大小为50,使用50个GRF函数,每个GRF使用1024个随机傅里叶特征(RFF),相关长度为2。
3.2.2.2 阶段二:权重优化
固定隐藏层参数 
 后,求解PDE转化为一个线性最小二乘问题:
后,求解PDE转化为一个线性最小二乘问题:


其中:

 是基函数矩阵,第
是基函数矩阵,第 
 列为
列为 


 是拉普拉斯算子作用在基函数上的结果
是拉普拉斯算子作用在基函数上的结果
 是边界上的基函数值
是边界上的基函数值
 是输出层权重(包括偏置)
是输出层权重(包括偏置)
 是边界条件的惩罚权重
是边界条件的惩罚权重
将PDE残差和边界条件组合成一个增广系统:


使用PyTorch的 torch.linalg.lstsqtorch.linalg.lstsq 求解器直接得到最优权重 。
3.2.3 实验设置
| 参数 | 说明 |
|---|---|
| 问题域 |   |
| 隐藏层神经元数 | 500 |
| 采样半径 | 1.5 |
| 形状参数 | 通过GRF搜索得到(约2-4之间) |
| PDE采样点 |   个规则网格点 个规则网格点 |
| 边界采样点 | 200个点(每条边50个) |
| 边界惩罚权重 | 1.0 |
3.2.4 实验结果与分析
TransNet 在二维泊松方程上展现了优异的求解能力。
从误差评估图可以看出:
- TransNet 能够高精度地逼近精确解


- 预测解的等高线图与精确解高度一致
- 绝对误差在整个求解域内保持在较低水平
- PDE残差在大部分区域都很小,分布均匀,没有出现局部异常
TransNet 证明了迁移学习在科学计算领域的巨大潜力。通过构建可迁移的神经特征空间,可以在保持高精度的同时显著提高计算效率,为实际工程应用中的PDE快速求解提供了新的思路。
4 总结与展望
基于上述实验与分析,可以得出以下结论:
PINN 在求解简单PDE问题时,是一种非常稳健且精度高的方法,尽管其计算成本(由于高阶导数)略高于Ritz方法。
Deep Ritz Method 作为一种基于物理变分原理的方法,概念上非常优雅,但在实践中可能对参数和实现细节更为敏感,需要仔细调优才能达到理想效果。
TransNet 代表了未来一个重要的发展方向。通过“预训练-微调”范式,可以大幅降低求解新问题的成本,实现快速、高效的PDE求解。
后续研究可进一步探索更复杂的PDE问题,例如非线性方程或时变问题,并深入理解TransNet的训练机制与工作原理。