好友关注
9.1 关注和取消关注
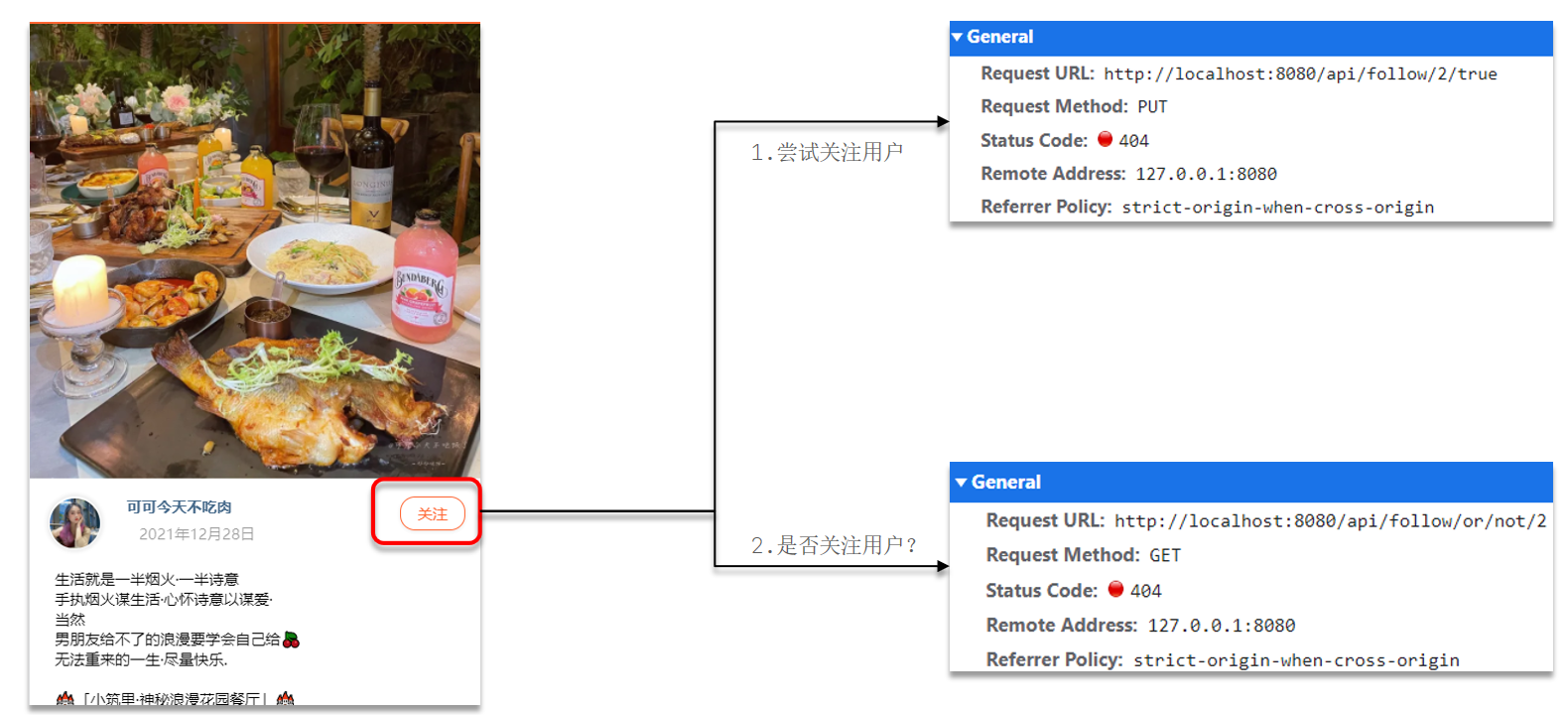
在博客详情页面中,用户可以关注和取消关注其他用户。这个功能涉及到两个主要的 API 请求:
- 尝试关注用户。
- 查询是否已关注用户。
/**
* 根据 isFollow 执行关注或取关 followUserId
* * @param followUserId
* @param isFollow
* @return
*/
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long followUserId, @PathVariable("isFollow") Boolean isFollow) {
return followService.follow(followUserId, isFollow);
}
/**
* 判断当前用户是否关注 followUserId
* @param followUserId
* @return
*/
@GetMapping("or/not/{id}")
public Result isFollow(@PathVariable("id") Long followUserId) {
return followService.isFollow(followUserId);
}/**
* 根据 isFollow 执行关注或取关 followUserId
* @param followUserId
* @param isFollow
* @return
*/
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1. 获取登陆用户
Long userId = UserHolder.getUser().getId();
// 2. 判断关注还是取关
if (isFollow) {
// 2. 关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
save(follow);
} else {
// 3. 取关,删除数据
remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
} return Result.ok();
}
/**
* 判断当前用户是否关注 followUserId
* @param followUserId
* @return
*/
@Override
public Result isFollow(Long followUserId) {
// 1. 获取登陆用户
Long userId = UserHolder.getUser().getId();
// 2. 查询是否关注
Integer count = query().eq("follow_user_id", followUserId).eq("user_id", userId).count();
return Result.ok(count > 0);
}9.2 共同关注
利用 Redis 中的 Set,实现共同关注功能:在博主个人页面展示当前用户与博主的共同关注好友。
- 两个用户的关注列表分别存储到 Redis 的 Set 集合中。
- 利用 Set 集合的交集操作,找出两个用户的共同关注好友。
@Override
public Result follow(Long followUserId, Boolean isFollow) {
// 1. 获取登陆用户
Long userId = UserHolder.getUser().getId();
String key = FOLLOW_KEY + userId;
// 2. 判断关注还是取关
if (isFollow) {
// 2. 关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
if (isSuccess) {
stringRedisTemplate.opsForSet().add(key, followUserId.toString());
}
} else {
// 3. 取关,删除数据
remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
} return Result.ok();
}/**
* 获取当前登陆用户与 id 用户的共同关注
*
* @param id
* @return
*/
@Override
public Result followCommon(Long id) {
// 1. 获取登陆用户
Long userId = UserHolder.getUser().getId();
// 2. 求交集
String key = FOLLOW_KEY + userId;
String key2 = FOLLOW_KEY + id;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, key2);
if (intersect == null || intersect.isEmpty()) {
return Result.ok();
}
// 3. 解析 id 集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
// 4. 查询用户
List<UserDTO> userDTOS = userService.listByIds(ids)
.stream()
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
.collect(Collectors.toList());
return Result.ok(userDTOS);
}9.3 Feed 流实现方案
当用户关注了其他用户后,系统会将这些被关注用户发布的新动态推送给关注者。这种机制即为关注推送,又称 Feed 流。
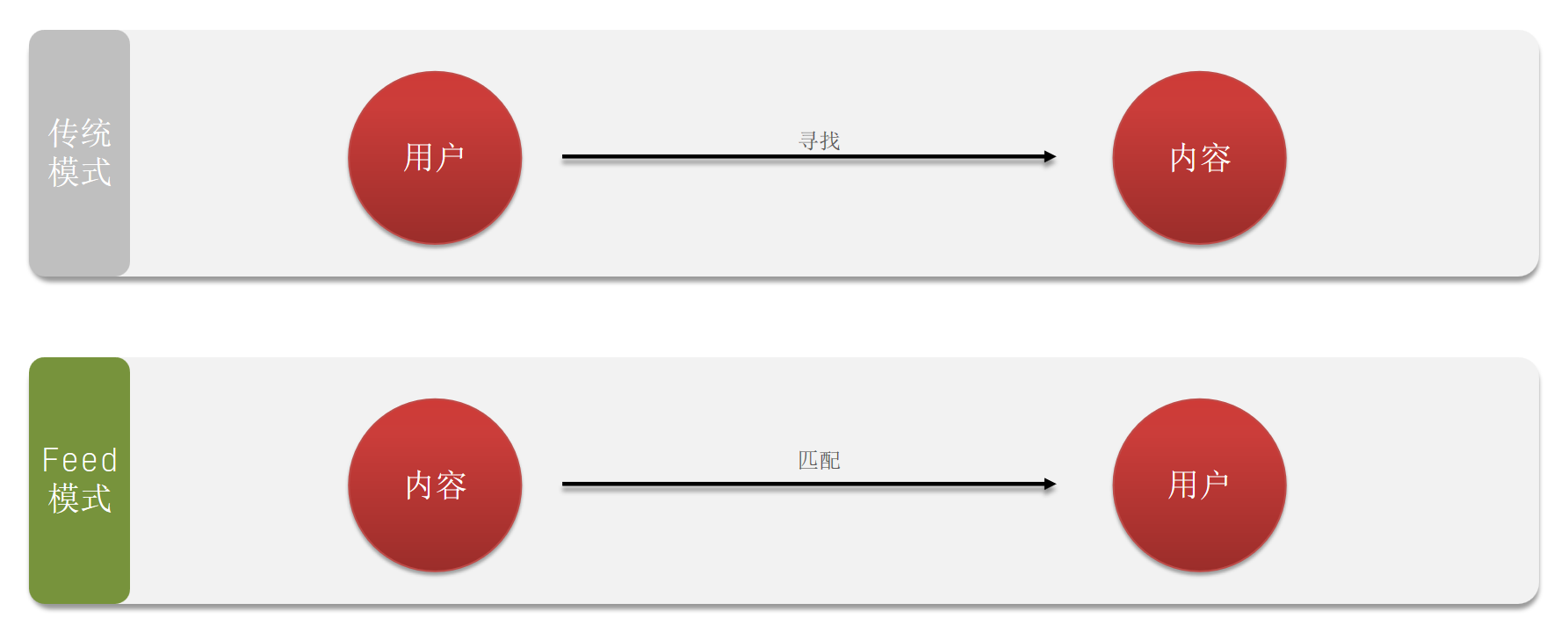
Feed 流旨在为用户提供持续的 “沉浸式” 体验,通过无限下拉刷新获取新的信息,减少用户主动搜索内容的需求。
传统模式下,用户需要主动通过搜索引擎或其他方式寻找内容。而新型 Feed 流则通过系统分析用户喜好,主动推送用户感兴趣的内容,从而节省用户时间,提高内容获取效率。
Feed 流产品主要有两种模式:
Timeline(时间线):不做内容筛选,简单地按照内容发布时间排序,常用于好友或关注的内容展示,例如朋友圈。
- 优点:信息全面,不会有缺失,实现相对简单。
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低。
智能排序:利用智能算法屏蔽违规和用户不感兴趣的内容,推送用户感兴趣的信息,从而吸引用户。
- 优点:投喂用户感兴趣的信息,用户粘度很高,容易沉迷。
- 缺点:如果算法不精准,可能适得其反。
为实现关注推送,我们采用 Timeline 方式,只需要拿到我们关注用户的信息,然后按照时间排序即可。
Timeline 模式有三种常见的实现方案:
- 拉模式 (Pull)
- 推模式 (Push)
- 推拉结合模式 (Mix)
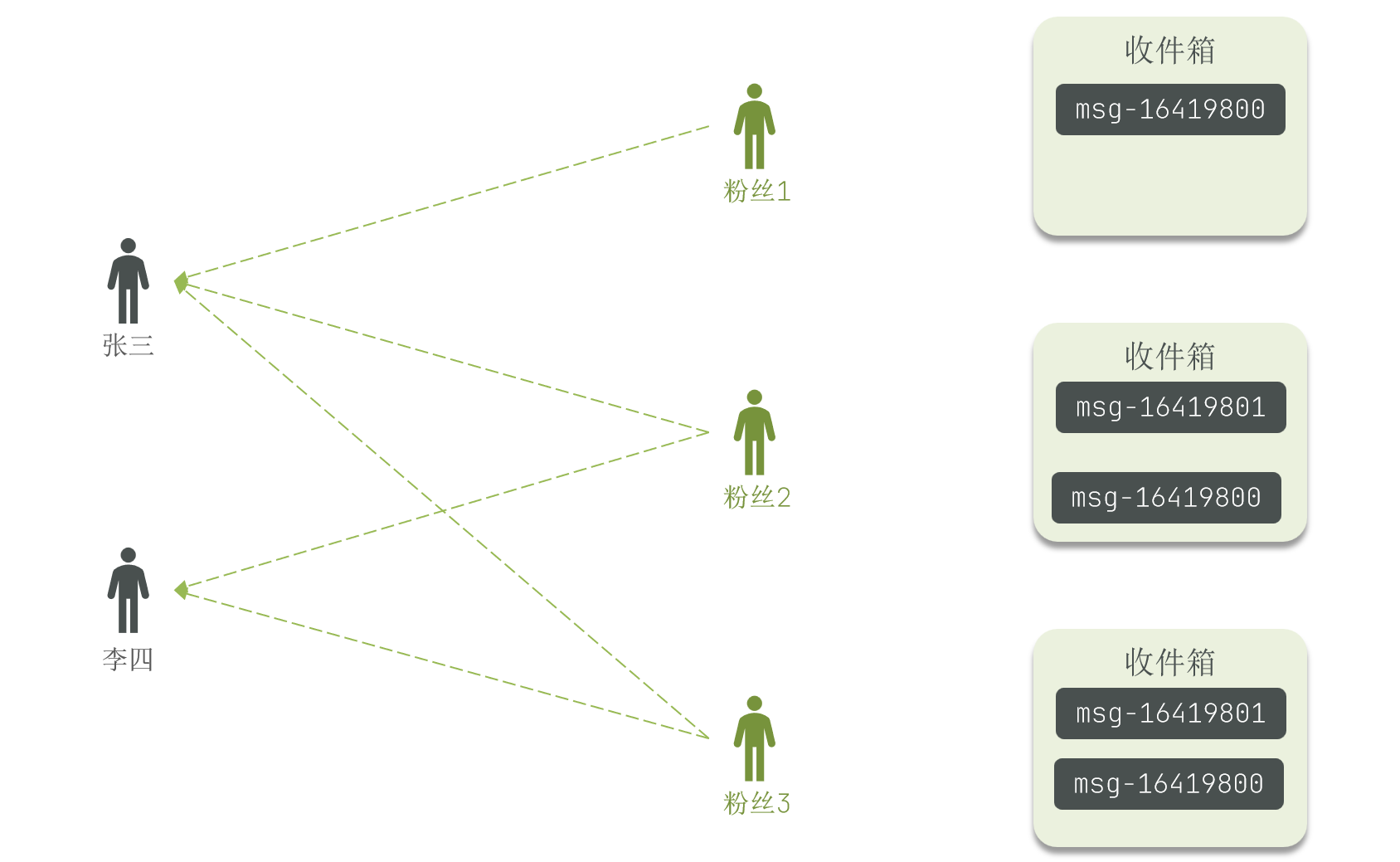
拉模式 (Pull):也叫做读扩散 (Read Fan-out)
- 原理:博主发布消息后,消息保存在自己的发件箱中。当粉丝要读取信息时,系统会从其关注的博主的发件箱中拉取所有信息,并进行排序。
- 优点:节省存储空间,因为只在粉丝读取信息时才拉取,读取完可以清除收件箱。
- 缺点:延迟较高,用户读取数据时才去拉取关注的人的信息。如果用户关注了大量博主,拉取海量内容会对服务器造成巨大压力。

推模式 (Push):也叫做写扩散 (Write Fan-out)
- 原理:博主发布消息后,系统主动将消息推送到所有粉丝的收件箱中。粉丝读取时,直接从自己的收件箱获取,无需临时拉取。
- 优点:时效性快,无需临时拉取。
- 缺点:内存压力大,如果大 V 发布消息,需要写入大量数据到粉丝的收件箱中。
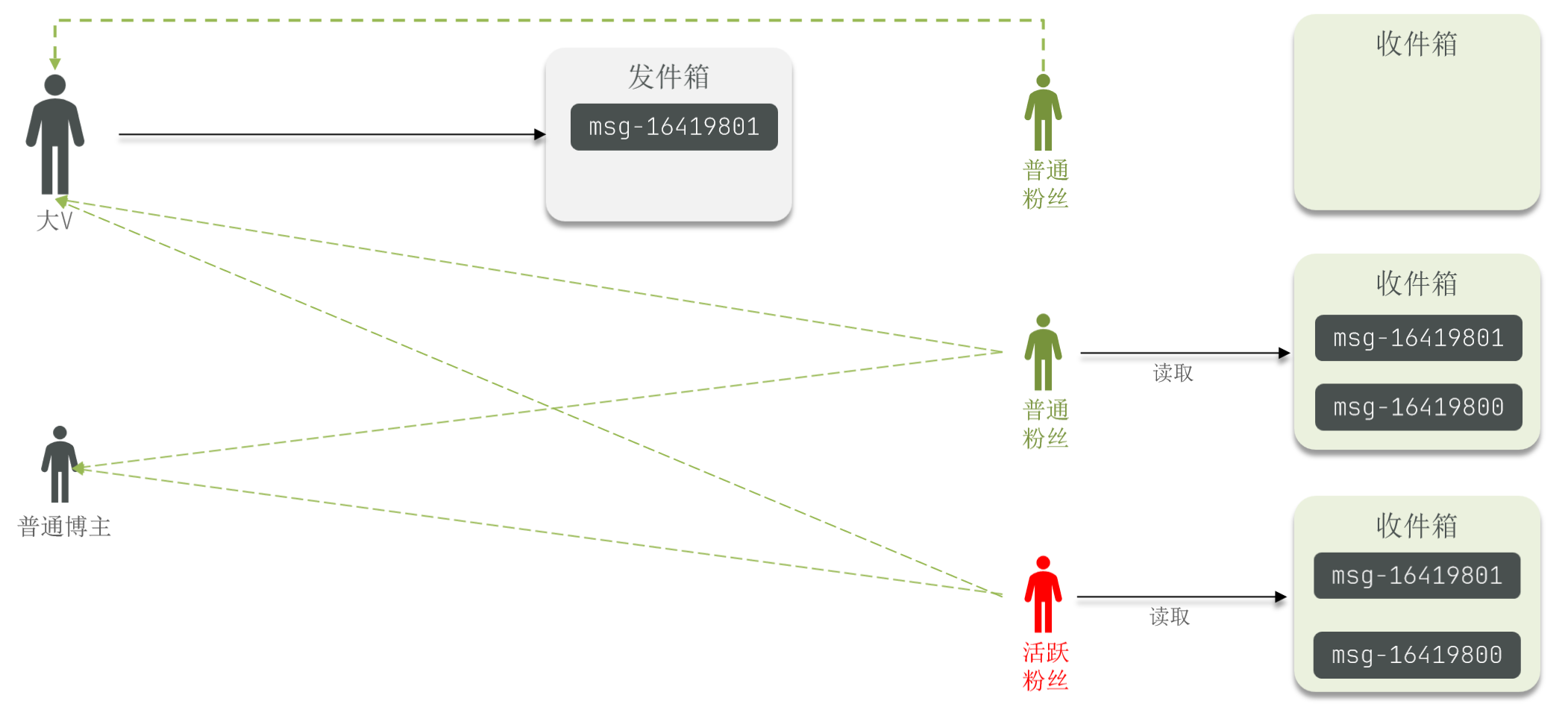
推拉结合模式 (Mix):也叫做读写混合
- 原理:兼具推模式和拉模式的优点,是一种折中的方案。
- 对于普通博主:采用写扩散的方式,直接将数据写入到粉丝的收件箱中,因为普通博主的粉丝数量较少,压力不大。
- 对于大 V 博主:先将数据写入到发件箱中,然后直接写入一份到活跃粉丝的收件箱中。
- 对于活跃粉丝:大 V 和普通博主发布的消息都会直接写入到自己的收件箱中。
- 对于普通粉丝:由于上线频率不高,上线时再从关注的大 V 博主的发件箱中拉取信息。
- 原理:兼具推模式和拉模式的优点,是一种折中的方案。
Feed 流的实现方案:
| 拉模式 | 推模式 | 推拉结合 | |
|---|---|---|---|
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 实现难度 | 复杂 | 简单 | 很复杂 |
| 使用场景 | 很少使用 | 用户量少、没有大 V | 过千万的用户量,有大 V |
9.4 关注推送
为了实现基于推模式的关注推送功能,需要满足以下几个核心需求:
- 实时推送:在保存 Blog 到数据库的同时,将 Blog 推送到所有粉丝的收件箱中。
- 有序存储:使用 Redis 的数据结构,保证收件箱中的数据按照时间戳排序,以便于按照时间顺序展示内容。
- 分页查询:提供分页查询收件箱数据的功能,允许用户按页浏览内容。
9.4.1 推送到粉丝收件箱
在 Blog 保存成功后,立即查询该 Blog 作者的所有粉丝,并将该 Blog 的 ID 推送到每个粉丝的 Sorted Set 结构中,以此模拟消息队列的推送功能。
/**
* 保存博客
* @param blog
* @return
*/
@Override
public Result saveBlog(Blog blog) {
// 1. 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2. 保存探店博文
boolean isSuccess = save(blog);
if (!isSuccess) {
return Result.fail(BLOG_SAVE_FAILED);
}
// 3. 查询博文作者所有粉丝
List<Follow> fans = followService.query().eq("follow_user_id", user.getId()).list();
// 4. 推送博文 id 给所有粉丝
for (Follow fan : fans) {
Long fanId = fan.getUserId();
stringRedisTemplate.opsForZSet().add(FEED_KEY + fanId, blog.getId().toString(), System.currentTimeMillis());
}
// 5. 返回id
return Result.ok(blog.getId());
}9.4.2 分页查询收件箱
传统的基于 page 和 size 的分页方法不适用于 Feed 流场景。原因是 Feed 流中的数据会实时更新,如果在两次分页查询之间有新的数据插入,可能会导致数据重复读取或遗漏。
设想这样的场景:假设在 t1 时刻,用户请求第一页数据(page = 1,size = 5),返回了时间戳为 10 到 6 的记录。此时,记录下最后一条记录的时间戳 6。在 t2 时刻,有新的记录(时间戳为 11)发布。t3 时刻,用户请求第二页数据(page = 2,size = 5)。如果仍然从传统分页的逻辑出发,则会从时间戳为 6 的位置开始读取,导致读取到重复的数据(6 到 2)。
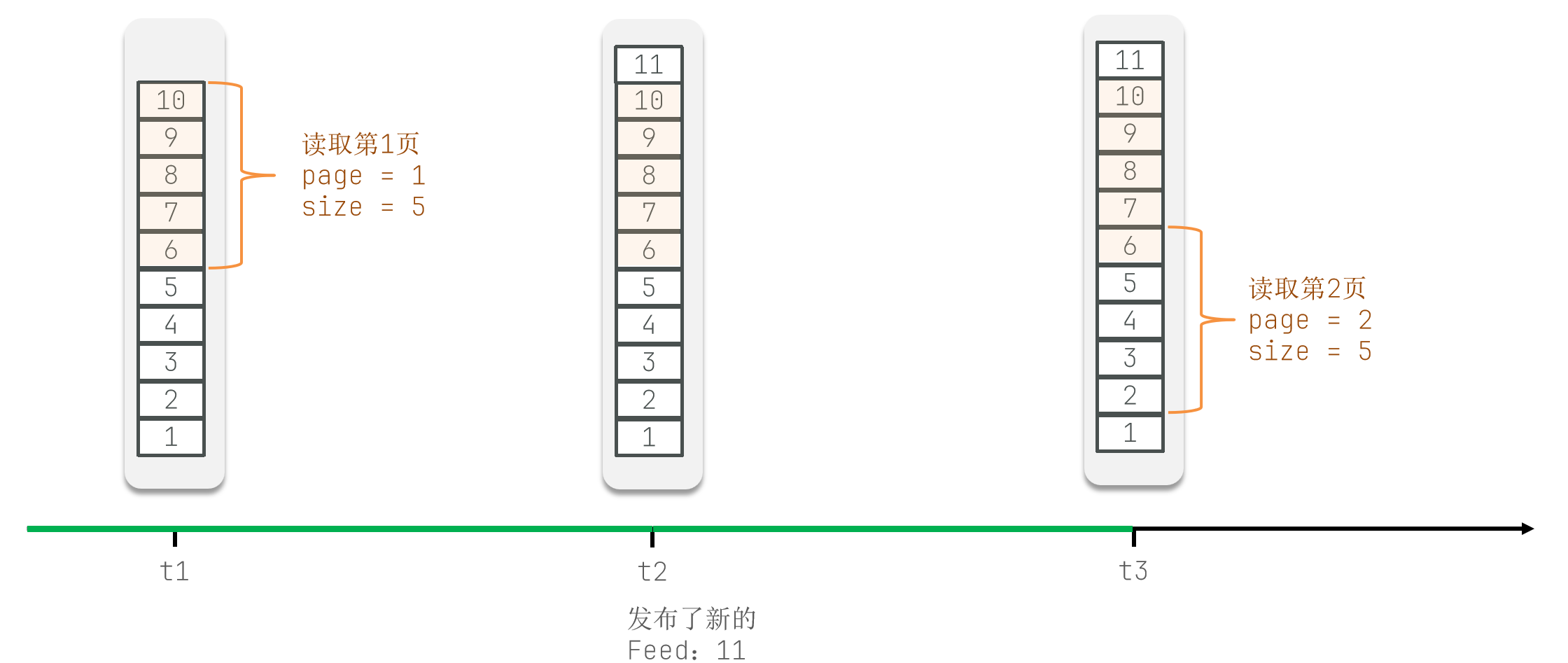
为避免重复读取,Feed 流分页需要记录每次操作的最后一条记录,并在下次查询时从该记录之后开始读取数据。回到上面的例子:
t1时刻,获取第一页数据,得到时间戳为10到6的记录,记录下最后一条记录的时间戳6。t2时刻,发布一条新的记录,时间戳为11。 这不会影响之前记录的时间戳6。t3时刻,获取第二页数据,从时间戳6之后的位置开始读取,得到时间戳为5到1的记录。
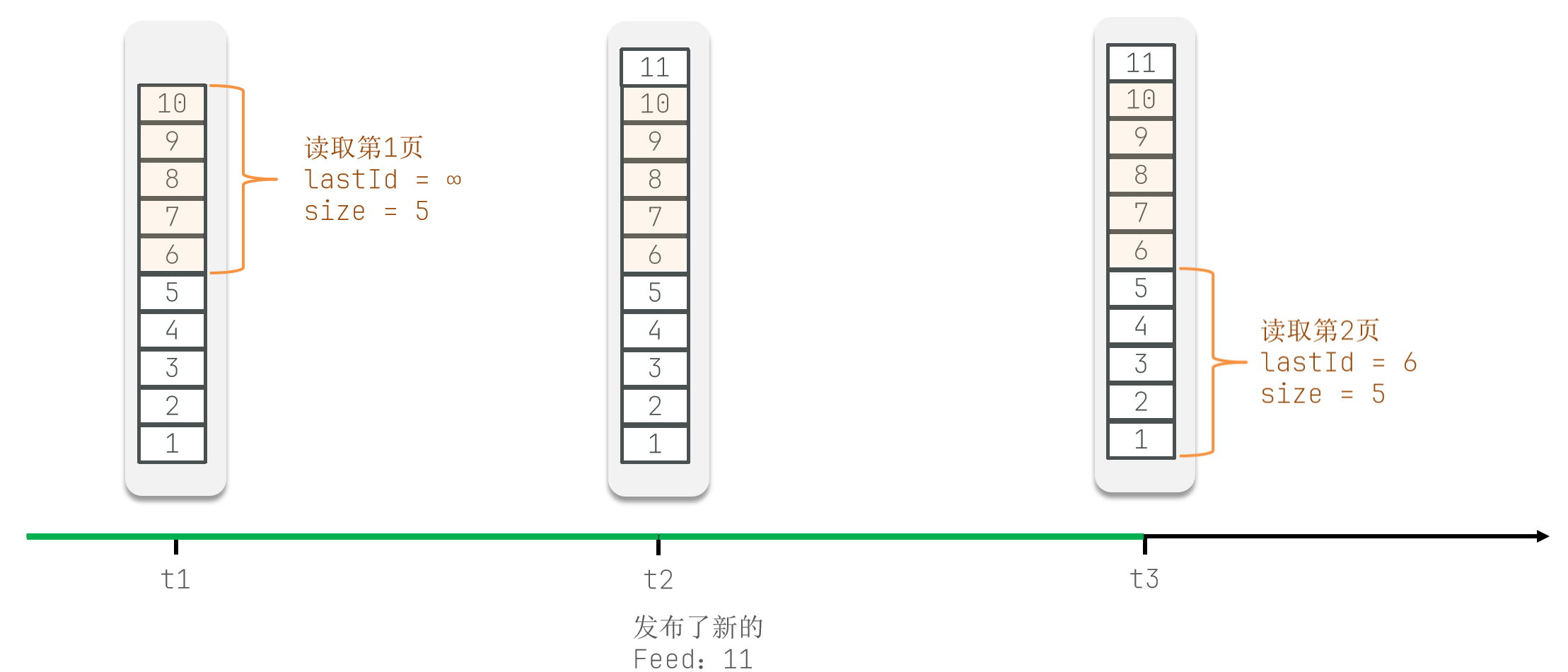
因此,可以使用 Redis 的 Sorted Set 数据结构来实现 Feed 流的滚动分页功能。Sorted Set 具有以下特性,使其非常适合该场景:
- 范围查询:可以根据 score (时间戳)进行范围查询,获取指定时间范围内的数据。
- 有序存储:元素按照 score 排序,保证 Feed 流按照时间顺序展示。
- 记录最小值:可以方便地记录当前获取数据的时间戳最小值,用于实现滚动分页。
通过 Sorted Set,可以避免传统分页中的数据重复和遗漏问题,实现高效、准确的 Feed 流分页功能。
/**
* 根据最新时间戳 max 和偏移量 offset 完成 Feed 流分页
* @param max
* @param offset
* @return
*/
@GetMapping("/of/follow")
public Result queryBlogOfFollow(@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset) {
return blogService.queryBlogOfFollow(max, offset);
}/**
* 根据最新时间戳 max 和偏移量 offset 完成 Feed 流分页
*
* @param max
* @param offset
* @return
*/
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1. 获取当前登陆用户
Long userId = UserHolder.getUser().getId();
// 2. 查询收件箱
Set<ZSetOperations.TypedTuple<String>> inbox = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(
FEED_KEY + userId,
0,
max,
offset,
2
);
if (inbox == null || inbox.isEmpty()) {
return Result.ok();
} // 3. 解析数据: blogId, minTime, offset
List<Long> ids = new ArrayList<>(inbox.size());
long minTime = 0;
int offsetNew = 1;
for (ZSetOperations.TypedTuple<String> email : inbox) {
// 3.1 获取 blogId ids.add(Long.valueOf(email.getValue()));
// 3.2 获取时间戳
long time = email.getScore().longValue();
if (time == minTime) {
offsetNew++;
} else {
minTime = time;
offsetNew = 1;
} } // 4. 根据 blogId 查询 blog String idsStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id, " + idsStr + ")").list();
for (Blog blog : blogs) {
// 5.1 查询 blog 作者信息
queryBlogUser(blog);
// 5.2 查询当前登陆用户是否点赞该 blog isLikedBlog(blog);
} // 6. 封装并返回
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setOffset(offsetNew);
scrollResult.setMinTime(minTime);
return Result.ok(scrollResult);
}