SQL优化
3.1 插入数据
3.1.1 INSERT 语句优化
如果需要一次性向数据库表中插入多条记录,可以从以下三个方面进行优化:
优化方案一:批量插入数据
使用一条
INSERT语句插入多条记录,例如:INSERT INTO tb_test VALUES (1, 'Tom'), (2, 'Cat'), (3, 'Jerry');相比于多条
INSERT语句,批量插入可以减少客户端与数据库之间的交互次数,从而提高效率。优化方案二:手动控制事务
将多条
INSERT语句放在一个事务中,手动控制事务的开始和结束,例如:START TRANSACTION; INSERT INTO tb_test VALUES (1, 'Tom'), (2, 'Cat'), (3, 'Jerry'); INSERT INTO tb_test VALUES (4, 'Tom'), (5, 'Cat'), (6, 'Jerry'); INSERT INTO tb_test VALUES (7, 'Tom'), (8, 'Cat'), (9, 'Jerry'); COMMIT;这样做可以减少事务的提交次数,降低数据库的
I/O压力。优化方案三:主键顺序插入
主键顺序插入的性能要高于乱序插入。这是因为在 InnoDB 存储引擎中,表数据都是根据主键顺序组织存放的。如果主键是乱序插入,会导致频繁的页分裂,从而影响性能。
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3 主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89
3.1.2 大批量插入数据
如果一次性需要插入大批量数据(比如:几百万的记录),使用 INSERT 语句插入性能较低,此时可以使用 MySQL 数据库提供的 LOAD 指令进行插入。
可以通过执行如下指令,将数据脚本文件中的数据加载到表结构中:
-- 客户端连接服务端时,加上参数 --local-infile
mysql --local-infile -u root -P
-- 设置全局参数 local_infile 为 1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行 load 指令将准备好的数据,加载到表结构中
LOAD DATA LOCAL INFILE '/root/sql1.log'
INTO TABLE tb_user
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';FIELDS TERMINATED BY ','指定字段之间的分隔符为逗号。LINES TERMINATED BY '\n'指定行之间的分隔符为换行符。
执行 LOAD DATA LOCAL INFILE 语句时,主键顺序插入的性能要高于乱序插入。
3.2 主键优化
3.2.1 数据组织方式
在 InnoDB 存储引擎中,表数据是根据主键(Primary Key)顺序组织存放的,这种存储方式的表被称为索引组织表 (Index Organized Table, IOT)。所有行数据都存储在聚集索引(Clustered Index)的叶子节点上。
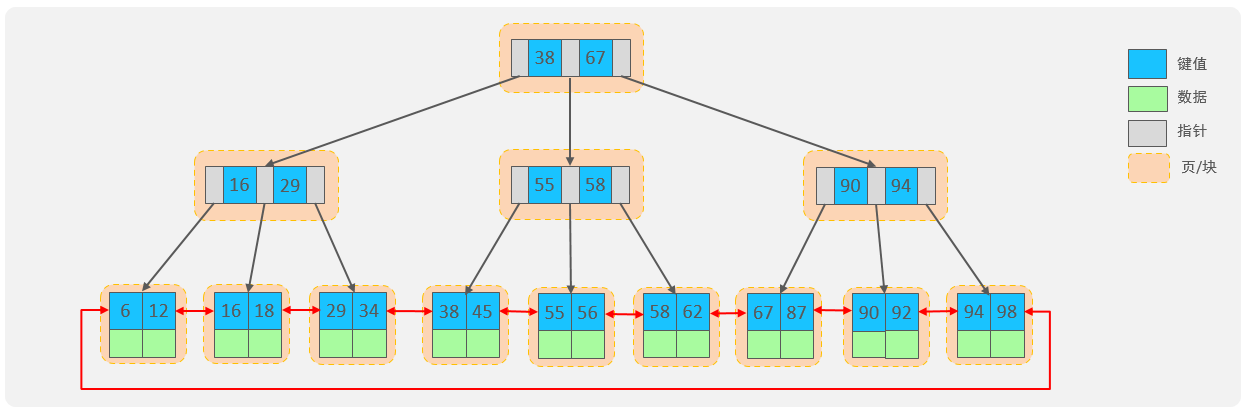
InnoDB 的逻辑存储结构从大到小依次为:表空间(Tablespace)、段(Segment)、区(Extent)、页(Page)、行(Row)。
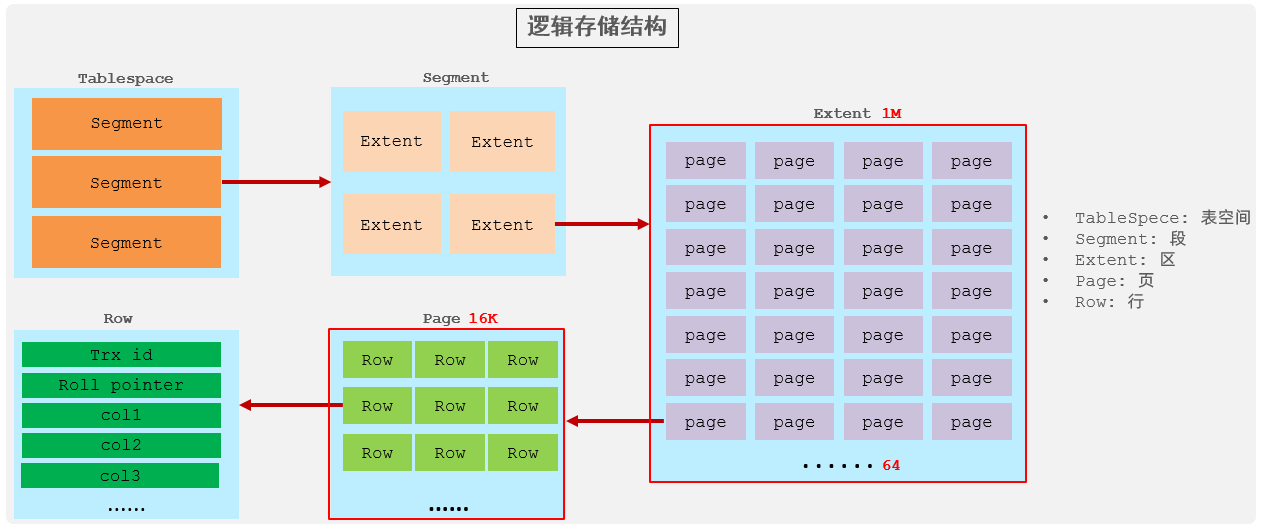
- 表空间 (Tablespace):
InnoDB存储数据的最高层逻辑单位。 - 段 (Segment):表空间由多个段组成,常见的有数据段、索引段、回滚段等。
- 区 (Extent):一个区包含连续的 1MB 存储空间。
- 页 (Page):页是
InnoDB管理磁盘的最小单位,默认大小为 16KB。所有数据行都记录在页中。 - 行 (Row):每一条记录的数据。
一个页中所能存储的行是有限的。如果插入的数据行 row 在当前页无法完全存储(例如行数据过大或者页已满),将会存储到下一个页中。页与页之间通过指针连接,形成双向链表结构,保持页的逻辑顺序。
3.2.2 页分裂
页可以为空,也可以填充一半,甚至可以填充 100%。每个页通常至少包含 2 行数据(如果一行数据过大,会发生行溢出)。页中的数据行根据主键顺序排列。
主键顺序插入效果:当主键按顺序插入时,InnoDB 会尝试将新数据添加到当前页。
- 初始状态:一个页(例如 1# page)未满,包含若干行数据。
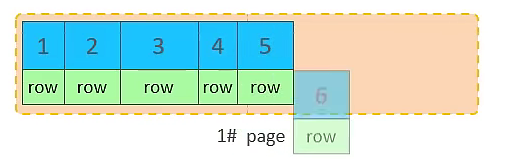
- 继续插入:新的行数据会继续插入到 1# page 中,直到该页写满。
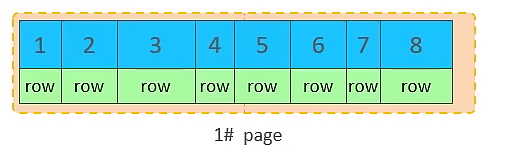
- 页满后:当 1# page 写满后,再写入的数据会开辟一个新的页(例如 2# page),并将其通过指针与 1# page 连接。

- 持续插入:随着数据不断插入,当 2# page 也写满后,会继续开辟 3# page,并将其与 2# page 连接,以此类推。

主键顺序插入时,新数据总是追加到当前页的末尾,当当前页满时,才开辟新页,并保持页之间良好的顺序连接。这种方式效率较高,因为数据写入是顺序的,减少了随机 I/O 和页分裂的开销。
主键乱序插入效果:当主键乱序插入时,InnoDB 可能会面临性能挑战,主要表现为页分裂。
- 场景设定:假设 1# 页和 2# 页已经写满,并且页中的数据是根据主键有序排列的。

- 乱序插入:此时尝试插入一条
id为 50 的记录。由于索引结构的叶子节点是有序的,id为 50 的记录逻辑上应该存储在id为 47 的记录之后,即 1# 页中。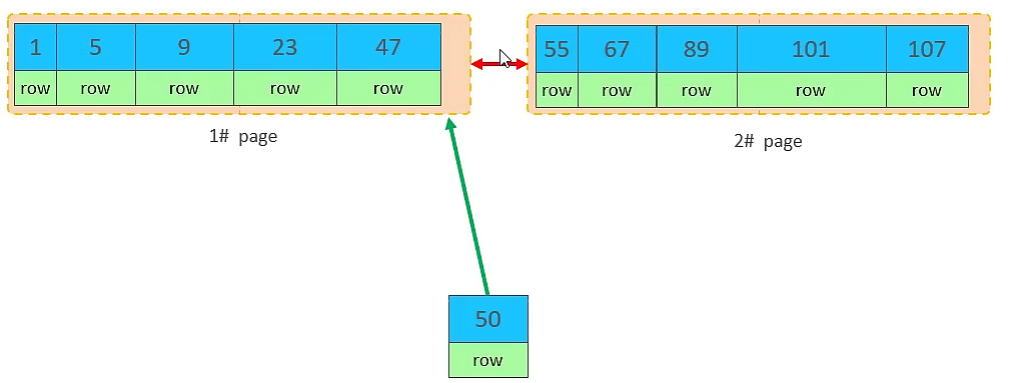
- 页满处理:然而,1# 页已经写满,无法直接插入
id为 50 的数据。 - 页分裂过程:
InnoDB会开辟一个新的页(例如 3# 页)。
- 为了保持数据的主键顺序,1# 页中一半的数据(通常是后一半数据)会被移动到新开辟的 3# 页中。

- 然后,
id为 50 的记录会插入到 3# 页的正确位置。
- 最后,为了维护页之间的逻辑顺序,需要重新设置页之间的链表指针,使得 1# 页的下一个页是 3# 页,而 3# 页的下一个页是 2# 页。

页分裂的本质:当一个数据页已满,但需要插入的新记录按主键顺序必须放在该页内部时,InnoDB 会创建一个新页,并将原页的一部分数据移动到新页,然后将新记录插入到正确的位置。这个过程会涉及大量的数据移动和指针重定向,导致磁盘 I/O 增加,性能下降。页分裂是比较耗费性能的操作。
3.2.3 页合并 (Page Merge)
当对已有数据进行删除操作时,会引发页合并的可能性,以优化空间使用。

- 数据删除:当删除一行记录时,实际上记录并不会被物理删除,而只是被标记 (flagged) 为删除状态。该行所占据的空间被标记为可用,允许其他记录声明使用。

- 空间回收:如果一个页中被标记为删除的记录达到
MERGE_THRESHOLD(默认是页的 50%),InnoDB会开始寻找最靠近的页(前一个或后一个)来尝试将两个页合并,以优化空间使用。
- 页合并过程:如果满足合并条件,两个相邻的页中的数据会被合并到一个页中,从而释放一个空页。

相关信息
MERGE_THRESHOLD 是一个可以自行设置的阈值,可以在创建表或创建索引时指定。
页合并的发生有助于回收因删除操作而产生的碎片空间,提高存储利用率。
3.2.4 索引设计原则
基于 InnoDB 的数据组织方式、页分裂与页合并的原理,设计主键时应遵循以下原则:
- 满足业务需求的情况下,尽量降低主键的长度:短主键可以减少索引占用的存储空间,提高缓存命中率,减少磁盘 I/O。
- 插入数据时,尽量选择顺序插入,推荐使用
AUTO_INCREMENT自增主键:顺序插入可以避免频繁的页分裂,提高插入性能。AUTO_INCREMENT是实现顺序插入的理想方式,它保证了新插入的主键值总是大于之前的主键值,从而确保数据按顺序追加到页的末尾或新页中,大大减少了页分裂的发生。
3.3 ORDER BY 优化
MySQL 中,对查询结果进行排序有两种方式:
Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作。所有不是通过索引直接返回排序结果的排序都称为FileSort排序。这种方式性能相对较低。Using index:通过有序索引顺序扫描直接返回有序数据,无需额外的排序操作,效率较高。
优化排序操作的目标是尽量避免 Using filesort,尽可能地使用 Using index。
接下来,通过一个测试来演示 ORDER BY 的优化策略:
数据准备
删除已存在的索引:
drop index idx_user_phone on tb_user; drop index idx_user_phone_name on tb_user; drop index idx_user_name on tb_user;执行排序 SQL
执行以下 SQL 语句,根据
age字段进行排序:mysql> explain select id,age,phone from tb_user order by age;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+----------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 24 | 100.00 | Using filesort | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+----------------+ 1 row in set, 1 warning (0.00 sec) ```
由于 `age` 和 `phone` 都没有索引,所以排序时会出现 `Using filesort`,导致排序性能较低。
创建索引
为了优化排序,可以创建一个包含
age和phone字段的联合索引:create index idx_user_age_phone_aa on tb_user (age,phone);创建索引后,根据
age进行升序排序创建索引后,再次执行排序查询:
mysql> explain select id, age, phone from tb_user order by age;
+----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone_aa | 48 | NULL | 24 | 100.00 | Using index | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) ```
此时,查询计划会显示 `Using index`,表明排序操作直接利用了索引,避免了 `Using filesort`,从而提高了性能。
创建索引后,根据
age,phone进行降序排序如果需要降序排序,可以执行以下 SQL 语句:
mysql> explain select id, age, phone from tb_user order by age desc, phone desc ;
+----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+----------------------------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone_aa | 48 | NULL | 24 | 100.00 | Backward index scan; Using index | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+----------------------------------+ 1 row in set, 1 warning (0.00 sec) ```
虽然也会出现 `Using index`,但 `Extra` 列中可能会出现 `Backward index scan`。这表示 MySQL 正在反向扫描索引,因为默认情况下索引的叶子节点是从小到大排序的,而查询要求从大到小排序。在 MySQL 8 及更高版本中,可以使用降序索引来避免反向扫描。
根据
phone,age进行升序排序(phone在前,age在后)如果排序字段的顺序与索引字段的顺序不一致,例如:
mysql> explain select id, age, phone from tb_user order by phone, age;
+----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-----------------------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone_aa | 48 | NULL | 24 | 100.00 | Using index; Using filesort | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-----------------------------+ 1 row in set, 1 warning (0.00 sec) ```
由于排序时未遵循最左前缀法则,仍然会出现 `Using filesort`。
根据
age,phone进行排序,一个升序,一个降序如果排序规则不一致(一个升序,一个降序),例如:
mysql> explain select id, age, phone from tb_user order by age asc, phone desc ;
+----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-----------------------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone_aa | 48 | NULL | 24 | 100.00 | Using index; Using filesort | +----+-------------+---------+------------+-------+---------------+-----------------------+---------+------+------+----------+-----------------------------+ 1 row in set, 1 warning (0.00 sec) ```
由于创建索引时默认是升序排序,而查询时存在升序和降序的混合排序,此时会出现 `Using filesort`。
创建联合索引 (
age升序排序,phone倒序排序)为了解决上述问题,可以创建特定排序规则的联合索引:
create index idx_user_age_phone_ad on tb_user (age asc, phone desc);
通过上述测试,可以总结出 ORDER BY 优化的以下原则:
- 根据排序字段建立合适的索引。多字段排序时,需要遵循最左前缀法则,确保索引能够被有效利用。
- 尽量使用覆盖索引。如果查询的字段都在索引中,可以避免回表查询,提高性能。
- 多字段排序时,如果排序规则不一致(既有升序又有降序),需要注意联合索引在创建时的排序规则 (
ASC/DESC),使其与查询的排序规则相匹配。 - 如果不可避免地出现
filesort,对于大数据量的排序,可以适当增大排序缓冲区的大小sort_buffer_size(默认 256KB)。但需要注意的是,增加sort_buffer_size可能会消耗更多的内存资源。
好的,下面是对您提供的课件内容进行的整理和总结,形成一份详尽的笔记。
3.4 GROUP BY 优化
本节主要探讨索引对分组操作的影响,通过实验来观察索引如何提升 GROUP BY 语句的性能。
数据准备 首先,删除
tb_user表上的所有索引:drop index idx_user_pro_age_sta on tb_user; drop index idx_email_5 on tb_user; drop index idx_user_age_phone_aa on tb_user; drop index idx_user_age_phone_ad on tb_user;无索引情况下的分组查询
在没有任何索引的情况下,执行以下 SQL 语句,并查看其执行计划:
mysql> explain select profession, count(*) from tb_user group by profession ;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 24 | 100.00 | Using temporary | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------+ 1 row in set, 1 warning (0.00 sec) ``` - type 为 ALL :这意味着 MySQL 需要对整个 tb_user 表进行全表扫描。 - possible_keys 和 key 都为 NULL :这表明 MySQL 认为没有任何索引可以用于优化这个查询。因此,它选择进行全表扫描。 - Extra 为 Using temporary :这意味着 MySQL 需要创建一个临时表来存储 GROUP BY 的结果。 全表扫描后,MySQL 需要将数据放入临时表进行分组和计数,这会消耗大量的磁盘 I/O 和 CPU 资源。
创建索引后的分组查询
接下来,创建一个联合索引,包含
profession,age和status字段:create index idx_user_pro_age_sta on tb_user (profession, age, status);创建索引后,再次执行相同的 SQL 语句,并查看执行计划:
mysql> explain select profession, count(*) from tb_user group by profession ;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | index | idx_user_pro_age_sta | idx_user_pro_age_sta | 54 | NULL | 24 | 100.00 | Using index | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) ``` - type 为 index :这表示 MySQL 使用了索引来查找行,但不是通过直接查找特定的索引值,而是扫描整个索引。 - possible_keys 和 key 都显示为 idx_user_pro_age_sta :这表明 MySQL 能够使用 idx_user_pro_age_sta 索引来优化查询。 - Extra 为 Using index :这意味着 MySQL 可以直接从索引中获取所需的数据,而无需访问实际的数据行(数据表)。
联合索引与最左前缀法则
接下来,执行以下不同的分组查询 SQL 语句,并观察执行计划:
mysql> explain select profession, count(*) from tb_user group by profession, age;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | index | idx_user_pro_age_sta | idx_user_pro_age_sta | 54 | NULL | 24 | 100.00 | Using index | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) ```
```shell
mysql> explain select age, count(*) from tb_user group by age;
+----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+------------------------------+ | 1 | SIMPLE | tb_user | NULL | index | idx_user_pro_age_sta | idx_user_pro_age_sta | 54 | NULL | 24 | 100.00 | Using index; Using temporary | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+------------------------------+ 1 row in set, 1 warning (0.00 sec) ```
观察结果表明,当仅根据 `age` 字段进行分组时,执行计划中出现了 `Using temporary`,这意味着 MySQL 使用了临时表来完成分组操作。而当根据 `profession` 和 `age` 两个字段同时分组时,则没有出现 `Using temporary`。
这是因为对于分组操作,联合索引的使用也遵循最左前缀法则。当 `GROUP BY` 子句中的字段顺序与联合索引的字段顺序一致,或者说是联合索引的最左前缀时,MySQL 可以直接利用索引进行分组,避免了临时表的创建,从而提高了查询效率。
通过以上实验,可以得出以下优化 GROUP BY 语句的策略:
- 利用索引提高效率:在分组操作时,可以通过创建适当的索引来提高效率。索引可以帮助 MySQL 快速定位到需要分组的数据,避免全表扫描和临时表的创建。
- 遵循最左前缀法则:分组操作时,索引的使用同样需要满足最左前缀法则。这意味着
GROUP BY子句中的字段顺序应该与索引中的字段顺序一致,或者说是索引的最左前缀。
总而言之,合理地设计和使用索引,可以显著提升 GROUP BY 语句的性能。在实际应用中,需要根据具体的业务场景和查询需求,选择合适的索引策略。
3.5 LIMIT 优化
当数据量较大时,使用 LIMIT 进行分页查询,随着分页的页码增加,查询效率会显著降低。例如:
mysql> select * from tb_sku limit 0, 3;
+----+-----------------+-----------+-------+------+-----------+----------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------+----------+-------------+--------+
| id | sn | name | price | num | alert_num | image | images | weight | create_time | update_time | category_name | brand_name | spec | sale_num | comment_num | status |
+----+-----------------+-----------+-------+------+-----------+----------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------+----------+-------------+--------+
| 1 | 100000003145001 | 华为Meta1 | 87901 | 9961 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t5590/64/5811657380/234462/5398e856/5965e173N34179777.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t5590/64/5811657380/234462/5398e856/5965e173N34179777.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 真皮包 | viney | 白色1 | 39 | 0 | 1 |
| 2 | 100000003145002 | 华为Meta2 | 3 | 9946 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23998/350/2363990466/222391/a6e9581d/5b7cba5bN0c18fb4f.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23998/350/2363990466/222391/a6e9581d/5b7cba5bN0c18fb4f.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 拉拉裤 | 巴布豆 | 白色2 | 54 | 0 | 1 |
| 3 | 100000003145003 | 华为Meta3 | 78903 | 9993 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/25363/12/2929/274060/5c21df3aE1789bda7/030af31afd116ae0.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/25363/12/2929/274060/5c21df3aE1789bda7/030af31afd116ae0.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 拉杆箱 | 莎米特 | 白色3 | 7 | 0 | 1 |
+----+-----------------+-----------+-------+------+-----------+----------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------+----------+-------------+--------+
3 rows in set (0.00 sec)mysql> select * from tb_sku limit 1000000, 3;
+---------+-----------------------+-----------------+-------+-------+-----------+-------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------------+----------+-------------+--------+
| id | sn | name | price | num | alert_num | image | images | weight | create_time | update_time | category_name | brand_name | spec | sale_num | comment_num | status |
+---------+-----------------------+-----------------+-------+-------+-----------+-------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------------+----------+-------------+--------+
| 1000001 | 100000003145001000001 | 华为Meta1000001 | 92001 | 10000 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t18196/293/2136823958/421330/7e75be4b/5ae83333Nae68e60d.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t18196/293/2136823958/421330/7e75be4b/5ae83333Nae68e60d.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 老花镜 | 又一春 | 白色1000001 | 0 | 0 | 1 |
| 1000002 | 100000003145001000002 | 华为Meta1000002 | 52002 | 10000 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t18196/293/2136823958/421330/7e75be4b/5ae83333Nae68e60d.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t18196/293/2136823958/421330/7e75be4b/5ae83333Nae68e60d.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 老花镜 | 又一春 | 白色1000002 | 0 | 0 | 1 |
| 1000003 | 100000003145001000003 | 华为Meta1000003 | 70003 | 10000 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t18196/293/2136823958/421330/7e75be4b/5ae83333Nae68e60d.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t18196/293/2136823958/421330/7e75be4b/5ae83333Nae68e60d.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 老花镜 | 又一春 | 白色1000003 | 0 | 0 | 1 |
+---------+-----------------------+-----------------+-------+-------+-----------+-------------------------------------------------------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------------+----------+-------------+--------+
3 rows in set (3.79 sec)mysql> select * from tb_sku limit 5000000, 3;
+---------+-----------------------+-----------------+--------+-------+-----------+------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------------+----------+-------------+--------+
| id | sn | name | price | num | alert_num | image | images | weight | create_time | update_time | category_name | brand_name | spec | sale_num | comment_num | status |
+---------+-----------------------+-----------------+--------+-------+-----------+------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------------+----------+-------------+--------+
| 5000001 | 100000003145005000001 | 华为Meta5000001 | 83301 | 10000 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23416/164/1114672941/97718/7a52de73/5b51a552Na67d01ef.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23416/164/1114672941/97718/7a52de73/5b51a552Na67d01ef.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 休闲鞋 | 森马 | 白色5000001 | 0 | 0 | 1 |
| 5000002 | 100000003145005000002 | 华为Meta5000002 | 127202 | 10000 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23416/164/1114672941/97718/7a52de73/5b51a552Na67d01ef.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23416/164/1114672941/97718/7a52de73/5b51a552Na67d01ef.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 休闲鞋 | 森马 | 白色5000002 | 0 | 0 | 1 |
| 5000003 | 100000003145005000003 | 华为Meta5000003 | 145403 | 10000 | 100 | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23416/164/1114672941/97718/7a52de73/5b51a552Na67d01ef.jpg!q70.jpg.webp | https://m.360buyimg.com/mobilecms/s720x720_jfs/t23416/164/1114672941/97718/7a52de73/5b51a552Na67d01ef.jpg!q70.jpg.webp | 10 | 2019-05-01 00:00:00 | 2019-05-01 00:00:00 | 休闲鞋 | 森马 | 白色5000003 | 0 | 0 | 1 |
+---------+-----------------------+-----------------+--------+-------+-----------+------------------------------------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------------------------------------+--------+---------------------+---------------------+---------------+------------+-------------+----------+-------------+--------+
3 rows in set (17.48 sec)在执行 LIMIT 2000000, 10 这样的查询时,MySQL 需要先扫描并排序 2000010 条记录,然后只返回最后的 10 条,丢弃前面 2000000 条记录。这种先扫描大量数据再丢弃的方式导致查询代价非常大。
通常,可以通过创建覆盖索引来提高分页查询的性能。一种常见的优化方法是使用覆盖索引加子查询的方式。
mysql> explain select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2000010 | 100.00 | NULL |
| 1 | PRIMARY | t | NULL | eq_ref | PRIMARY | PRIMARY | 4 | a.id | 1 | 100.00 | NULL |
| 2 | DERIVED | tb_sku | NULL | index | NULL | PRIMARY | 4 | NULL | 2000010 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+---------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)这条 SQL 语句的核心在于利用子查询和覆盖索引来避免全表扫描。子查询 (SELECT id FROM tb_sku ORDER BY id LIMIT 2000000,10) 的作用是:
- 覆盖索引: 由于
id是主键,因此对id的查询可以直接使用主键索引,无需回表查询其他列的数据。Extra列的Using index也证实了这一点。 - 延迟关联: 子查询先通过索引快速定位到所需的
id范围,然后主查询再根据这些id值来获取完整的行数据。这避免了在整个大表中进行LIMIT操作,从而提高了性能。
3.6 COUNT 优化
在数据库性能测试中,当数据量庞大时,执行 COUNT 操作会显著增加耗时。这主要源于不同存储引擎的底层实现机制差异:
- MyISAM 引擎:将表的总行数持久化存储于磁盘中。当执行
COUNT(*)时,引擎直接返回该预存数值,效率极高。然而,对于带条件的COUNT(如WHERE子句),由于需逐行扫描,效率会显著降低。 - InnoDB 引擎:在执行
COUNT(*)时,必须从引擎中逐行读取数据并进行累积计数,导致高资源消耗。 为了提升 InnoDB 表的COUNT效率,核心优化思路是自行维护计数值。例如,借助外部数据库(如 Redis)存储计数器。该方法挑战在于处理带条件的COUNT,如涉及动态筛选条件时,维护开销会大幅增加,使其复杂性提升。
接下来,我们将详细解析 COUNT 的操作原理及其变体,提供具体优化依据。
COUNT 作为聚合函数,其工作机制是对结果集逐行判断:若参数值非 NULL,则累加器递增 1;否则跳过。最后返回累计值。主要用法包括 COUNT(*)、COUNT(主键)、COUNT(字段) 和 COUNT(数字)。下表详述了每种用法在 InnoDB 引擎中的行为:
COUNT 用法 | InnoDB 引擎行为 |
|---|---|
COUNT(主键) | 引擎遍历全表,提取每行的主键 id 值并返回至服务层。服务层直接按行累加(因主键永不 NULL)。 |
COUNT(字段) | 无 NOT NULL 约束:引擎遍历全表,提取每行字段值至服务层;服务层判断非 NULL 时累加。有 NOT NULL 约束:引擎提取字段值至服务层后,服务层直接按行累加。 |
COUNT(数字) | 引擎遍历全表但不取值;服务层为每行放置数字 1,并按行累加。 |
COUNT(*) | 引擎进行专门优化(不提取具体字段),服务层直接按行累加。 |
按照效率排序,COUNT(字段) < COUNT(主键 id) < COUNT(1) ≈ COUNT(*),因此,应优先使用 COUNT(*) 以最大化效率。其优化机制避免了不必要的数据提取,显著减少 I/O 开销。
3.7 UPDATE 优化
在执行 SQL UPDATE 语句时,需要特别注意锁机制对性能的影响。锁的粒度(行锁或表锁)直接决定操作的并发性和效率,优化不当会导致性能显著下降。
索引字段与行锁
基于索引列(如主键 id)执行 UPDATE:
UPDATE course SET name = 'javaEE' WHERE id = 1;该语句在执行时,InnoDB 引擎会根据 id = 1 的索引条件锁定对应的单行数据(行锁),确保数据一致性。事务提交后,行锁自动释放。这种锁机制允许高并发操作,因为锁的粒度小,仅影响特定记录。
非索引字段与锁升级
使用非索引列(如 name)执行 UPDATE:
UPDATE course SET name = 'SpringBoot' WHERE name = 'PHP';如果并发开启多个事务执行该语句,InnoDB 将原本的行锁升级为表锁,此时整个表被锁定。这种升级源于 WHERE name = 'PHP' 中 name 字段缺乏有效索引,导致索引失效。表锁降低了并发性和性能:其他事务的读写操作会被阻塞,直到当前事务释放表锁。
InnoDB 的行锁机制依赖于索引:锁是针对索引而非物理记录的抽象结构施加的。如果 WHERE 子句涉及未索引字段或索引失效(例如全表扫描),锁将从行级升级为表级。为优化性能,应确保 UPDATE 语句中的条件字段:
- 是有效的索引列(如主键或唯一索引)。
- 避免不必要的字段操作,以减少锁冲突和性能瓶颈。
通过优化索引设计,可以避免锁升级,维持高效的行锁并发处理能力。